phpMyAdminで始める初めてのデータベース設計 後半

皆様、いかがお過ごしであろうか? 今年の1~3月は多忙につきゾンビとして日の当たらぬ日々を送っていた野地である。ホントお久しぶりである。
今回は前回の続きで残りの3つのテーブルを作成するところまでを紹介したいと思う。
前回と今回をまとめて理解できれば実際のアプリケーションでも一通りのデータベース設計が行えるだろう。
今回のゴール
前回作成したuserテーブルを軸に残り3つのmemo, category, memo_category_relationテーブルを作成する。
新たに登場する型や、リレーショナルデータベースの最も得意とするところである複数のテーブルの関係と、逆に苦手とされてる木構造データの扱い方を紹介しながらの作成になるので、じっくりと理解しながらテーブルを作成してみて欲しい。
TEXT型
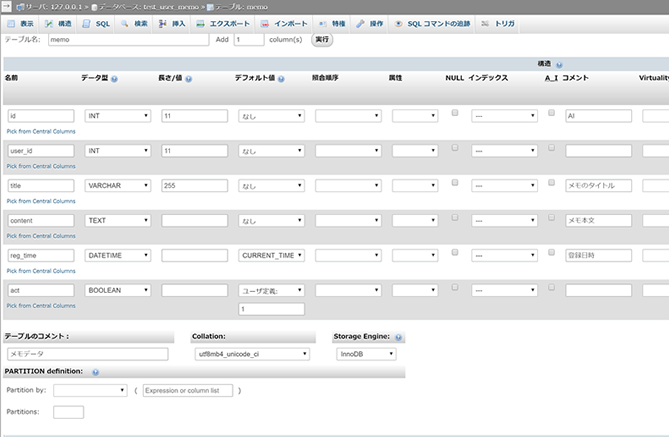
前回はuserテーブルを作成したので、今回はmemoテーブルの作成から始めよう。
memoテーブルのカラムは以下になる。
| 名前 | 説明 |
|---|---|
| id | 一意性を保つための数値。オートインクリメントを設定する。 |
| user_id | user テーブルの id |
| title | メモのタイトル。 |
| content | メモの内容 |
| reg_time | メモが作成された日時 |
| act | メモが削除されたかのboolean値。論理削除用。 |
id, actはそれぞれuserテーブルで指定したものと同じ役割なので説明は割愛する。ただし、actについては前回説明した複合インデックスをuser_idと一緒に張るのでuserという名前でインデックス設定を追加しておこう。
user_idについてはリレーションという概念に関わってくるのでリレーションとはにて説明しよう。
titleは長文を設定しないのでVARCHAR型の長さ255としている。もしタイトルに25文字も必要ないと判断したら長さは100でも50でもいいかもしれない。
| 欄 | 値 |
|---|---|
| 名前 | title |
| データ型 | VARCHAR |
| 長さ/値 | 255 |
| デフォルト値 | なし |
| NULL | 未チェック |
| インデックス | 未設定 |
| AI | 未チェック |
| コメント | メモのタイトル |
次にcontentだが、ここで初めて設定するデータ型であるTEXT型を設定する。
| 欄 | 値 |
|---|---|
| 名前 | content |
| データ型 | TEXT |
| 長さ/値 | 未定義 |
| デフォルト値 | なし |
| NULL | 未チェック |
| インデックス | 未設定 |
| AI | 未チェック |
| コメント | メモ本文 |
TEXT型はVARCHAR型と同じく文字列を格納するデータ型だが、明確に違うのは挿入可能なデータの大きさであり、TEXT型はVARCHAR型より多くの文字列を格納することができる。
ただし、TEXT型にも上限は存在し、
- TINYTEXT
- 255文字
- TEXT
- 65,535文字
- MEDIUMTEXT
- 16,777,215文字
- LONGTEXT
- 4,294,967,295文字
と、派生型によって上限文字数が異なる。ブログ記事一つ分くらいならTEXT型で十分事足りるはずだが、小説や論文データなどを格納する場合は章などで区切ることを検討した方が良いだろう。
なお、VARCHAR型とは異なり、上限値の長さはそのまま文字数ではなく、マルチバイト文字(日本語等)を使用するとそれだけ短くなる点にも注意。
このようにTEXT型は長文を格納するデータ型であるため、長さの設定も行わなくてよい。
では全ての、文字を格納するカラムはVARCHAR型ではなくTEXT型で設定すればいいのかと言うとそうでもない。
この連載では触れないが、TEXT型にはINDEXが効かないという弱点があり、検索効率がVARCHAR型に比べ極端に悪いという特徴がある。大雑把に言えばデータは大量に入るが、検索スピードが遅くなるのだ。
余談だが、ストレージエンジンが innodb である場合、両者の内部処理は一緒なので性能に違いはないらしい。しかし混乱を避けるためにも明示的な使い分けは必須だろう。
DATEETIME型
次にreg_timeだが、こちらはDATETIMEというデータ型を設定する。
| 欄 | 値 |
|---|---|
| 名前 | reg_time |
| データ型 | DATETIME |
| 長さ/値 | 未定義 |
| デフォルト値 | CURRENT_TIMESTAMP |
| NULL | 未チェック |
| インデックス | 未設定 |
| AI | 未チェック |
| コメント | 登録日時 |
JavaScriptやPHP等のプログラミング言語ではなかなかお目にかかれないが、SQLの世界では日付と時間型という型が独立して存在する。時間というデータはプログラミング言語では文字列であったり数値であったりするが、データベース上では時間による絞り込みや時間差の算出等をよく使うためであろう。
DATETIME型には「YYYY-mm-dd HH:ii:ss」という形で日時情報が入る。
日本語に直すと「西暦4桁+半角ハイフン+月2桁+半角ハイフン+日2桁+半角スペース+時2桁+半角コロン+分2桁+半角コロン+秒2桁」といった文字列を格納していると解釈して構わない。
DATETIME型には日時情報が全て入るため秒レベルまでのある一点を指し示すことができるが、日レベルまでで構わない場合はDATE型、逆に日付は不要の場合はTIME型を使用できるので覚えておくとよいだろう。
ちなみに現代の事象を扱う場合は全く注意する必要はないが、「YYYY」部分、つまり西暦部分においてMySQLが公式にサポートしているのは「1000」から「9999」までなので、奈良時代以前やSFレベルの未来を扱うときは注意した方がよい。
今回初めて設定するデフォルト値の「CURRENT_TIMESTAMP」だが、これはデータを挿入するときにreg_time型が未設定だったときにDBが把握している現在時刻をそのまま入れてくれる設定となる。大抵の場合はアプリケーション側で明示的な日時を指定するべきだが、保険的な意味でも設定しておくといいかもしれない。
リレーションとは
世の中には色々なデータベースが存在するが、MySQLはリレーショナルデータベースというデータベースに分類される。
リレーショナルとは日本語に訳すと「関連する」という意味だが、リレーショナルデータベースの場合はテーブル同士の関連を指す。
今回の例ではmemoテーブルも前回作成したuserテーブルに関連するテーブルだ。
さて、memoテーブルのuser_idカラムはどのユーザーがそのメモを作成したかを表すカラムである。
user_idカラムにはINT型を指定するが、このカラムにはuserテーブルのidと同じ情報を格納する。
こうすることで後からid: 1番を持つユーザーの作成したメモの一覧を検索することができるし、逆にあるメモを作成したユーザーのname、つまり名前情報等を取得することが可能になるわけだ。
ところで、そもそもなぜデータを複数のテーブルに分割するのだろうか。
これぞリレーショナルデータベースの真髄と言っても過言ではないのだが、それは「ユーザーというデータ」と「メモというデータ」の関係が1対1ではなく1対nだからである。
1対nという言い回しは、より分かりやすく言えば一つに対して複数が結びついている状態のことである。
user id: 1のAというユーザーがmemo id: 1, memo id: 2のメモ、user id: 2のBというユーザーがmemo id: 3のメモの作者というデータの作者だったとしよう。これを素直に表にするのであれば以下のようになる。
| user id | 作者の名前 | memo id | 所持するメモのタイトル |
|---|---|---|---|
| 1 | Aさん | 1 | すごいメモ |
| 1 | Aさん | 2 | あやしいメモ |
| 2 | Bさん | 3 | ただのメモ |
「Bさん」は「ただのメモ」しか所有していないので1対1の関係だが、「Aさん」は「すごいメモ」と「あやしいメモ」の二つを持っているので、「user id」列と「作者の名前」列が被っているのが分かるだろう。
人間にとっては見やすい表ではあるが、システムとして考えたとき「作者の名前」列データは冗長なデータである。
なぜなら「user id」がただ一つに定まれば「作者の名前」は自動的にただ一つに定まる、つまり「user id」が1ならば「作者の名前」は必ず「Aさん」になるからだ。
「Aさん」がメモを追加していく度に同じデータである「作者の名前」データが溜まっていくのは有限のハードディスクやSSDを使っている限りデータ容量の無駄である。
更に、そもそもメモを一つも持っていない「Cさん」が存在していた場合、この表から「Cさん」のデータを読み取ることは不可能である。
そこで過去の人々が考えたのがテーブルの分割、すなわちリレーショナルデータベースモデルである。
| user id | 作者の名前 |
|---|---|
| 1 | Aさん |
| 2 | Bさん |
| 3 | Cさん |
| user id | memo id | 所持するメモのタイトル |
|---|---|---|
| 1 | 1 | すごいメモ |
| 1 | 2 | あやしいメモ |
| 2 | 3 | ただのメモ |
このようにテーブルを分割することで、メモデータが溜まっていっても重複するデータは「user id」だけになるし、Cさんがメモを一つも持っていなくてもこのデータベースを使用しているシステムにCさんというユーザーが存在することは明らかだ。
後になって「Aさん」が「A`さん」に改名した際も、わざわざメモデータを格納しているテーブルの情報を上書きしなくても「すごいメモ」や「あやしいメモ」の持ち主名が「A`さん」になるというメリットもある。
このように表データを、人間が見るのではなく、コンピューターシステムによって取り回しやすいように変形することを「データベースの正規化」という。
この記事では正規化について詳しく説明しないが、この正規化を正しく行うことでデータの矛盾や余分を設計段階で防ぐことができる。
定義はもっと厳格なのだが、現時点ではとりあえず「1対1ではないデータはテーブルを分ける」ことを意識できれば十分だろう。
話を戻して、user_idカラムの設定は以下となる。
| 欄 | 値 |
|---|---|
| 名前 | user_id |
| データ型 | INT |
| 長さ/値 | 11 |
| デフォルト値 | なし |
| NULL | 未チェック |
| インデックス | INDEX(actとの複合インデックス user) |
| AI | 未チェック |
| コメント | user_id |
データ型と長さはuserテーブルのidと同じデータを格納するため条件も揃えよう。
また前述したactカラムとの複合インデックスも張っておくと「あるユーザーの削除されていないメモ」を検索するときの処理が高速になるだろう。
加えて時間指定をするのであればreg_time、タイトル検索をするならばtitle、といった具合に複合インデックスへの合成物を混ぜていくとより詳細な検索への高速化が見込める。
ただし、MySQL は一回の検索で使えるインデックスは一つだけという制約があるため、どんなインデックスをどれだけ用意するかは作成するサービスの検索種類・頻度によって調整すべきだ。
以上でmemoテーブルは完成である。
木構造の問題と解決モデルの紹介
メモができたら次にカテゴリーを扱うテーブルを作成しよう。
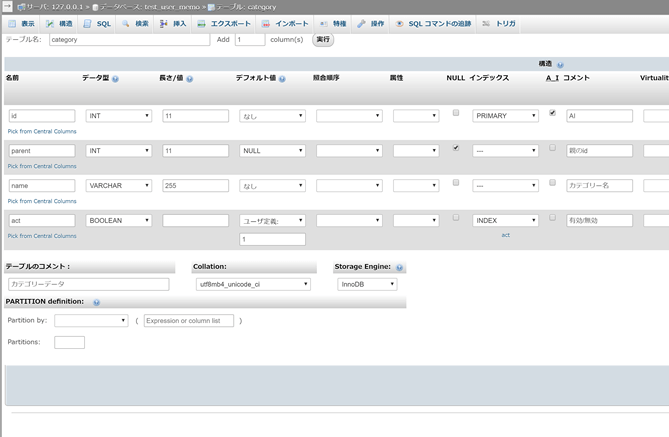
早速categoryテーブルの各カラムは以下の4つになる。
| 名前 | 説明 |
|---|---|
| id | 一意性を保つための数値。オートインクリメントを設定する。 |
| parent | 同テーブルのid。親子関係を表す。 |
| name | カテゴリー名。 |
| act | カテゴリーが削除されたかのboolean値。論理削除用。 |
id、actはそれぞれuser、memoと同じなので割愛する。
nameに関してもmemoのtitleと設定は同じなので更に割愛する。
このテーブルで唯一、新たな役割を持つのがparentカラムだ。
| 欄 | 値 |
|---|---|
| 名前 | parent |
| データ型 | INT |
| 長さ/値 | 11 |
| デフォルト値 | NULL |
| NULL | チェックを入れる |
| インデックス | 未設定 |
| AI | 未チェック |
| コメント | 親のid |
ここで初めてNULLが登場することになる。
プログラミング言語の経験が何かしらある人にはお馴染み(言語によってはnilだったりするだろうが)であるこのNULLは「データが無い」ことを表す言葉だが、SQL の世界ではカラムが NULL を許可する設定であればデータ型に関係なく設定できる値となる。プログラミング言語の世界では独立した型であることが多いので理解に注意が必要だ。
カラムに NULL を許容する場合は「NULL」にチェックを入れればOKである。
さて、このparentカラムの役割はカテゴリーの親子関係を表すことである。
NULLなら最上位のカテゴリー、parentに既存カテゴリーのidが設定されていればそれが親カテゴリーとなるといった具合に設定すれば、親は必ず一つ、子は複数の通称「木構造」を作ることができる。
例えば「重要」カテゴリーの子カテゴリーとして「予定」、「仕事」カテゴリーがあり、「仕事」カテゴリーの子カテゴリーとして「緊急」というカテゴリーがあったとするならばcategoryテーブルは以下のようになるだろう。
| id | name | paernt | act |
|---|---|---|---|
| 1 | 重要 | NULL | 1 |
| 2 | 予定 | 1 | 1 |
| 3 | 仕事 | 1 | 1 |
| 4 | 緊急 | 3 | 1 |
このようにすれば、
- ・直近の親を探す時は自身の
parentとidが一致するレコード(親) - ・直近の子を探す時は自身の
idと一致するparentを持つレコード(子) - ・自身と同じ親を持つカテゴリーを探す時は自身の
parentと一致するparentを持つレコード(兄弟)
という検索を行うことができる。
ただし、この設計には直近ではない親や子、つまり先祖レコードや子孫レコードを一発で取得できないという弱点が存在する。
これは通称「Adjacency List Model(隣接リストモデル, ナイーブツリー)」と呼ばれる設計モデルで、ある程度小規模な木構造ならあまり問題にならないが、大量のレコードを扱ったり高速な検索を行うには不向きだ。
今回は名前の紹介に留めるが、大規模な木構造データを実践開発する際は以下4種類の設計モデルを検討してみよう。
- Path Enumeration Model(経路列挙モデル)
- Nested Sets Model(入れ子集合列挙モデル)
- Closure Table Model(閉包テーブルモデル)
- Fertile Forest Model (肥沃な森林モデル)
中間テーブルで多対多へ対応する
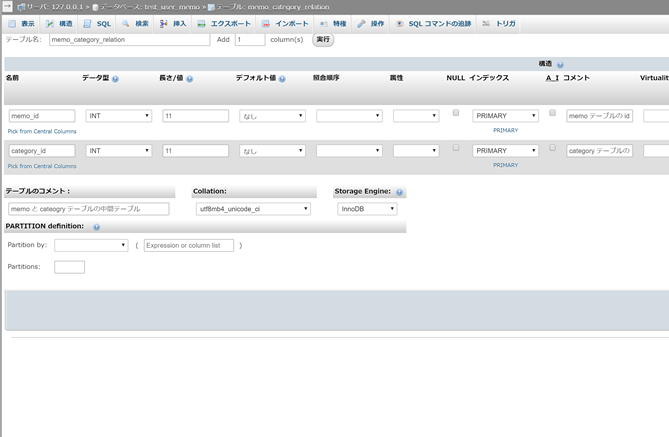
最後にmemo_category_relationテーブルを作成しよう。
今までは全てのテーブルにおいて最初のカラムとして AI + Primary 設定のidを設定してきたが、このテーブルのみ設定が違う。
| 名前 | 説明 |
|---|---|
| memo_id | memo テーブルの id |
| category_id | category テーブルの id |
このようにテーブルに必要なカラムは二つだけで、memo_idは、
| 欄 | 値 |
|---|---|
| 名前 | memo_id |
| データ型 | INT |
| 長さ/値 | 11 |
| デフォルト値 | なし |
| NULL | 未チェック |
| インデックス | Primary |
| AI | 未チェック |
| コメント | memo テーブルの id |
となり、category_idは、
| 欄 | 値 |
|---|---|
| 名前 | category_id |
| データ型 | INT |
| 長さ/値 | 11 |
| デフォルト値 | なし |
| NULL | 未チェック |
| インデックス | Primary |
| AI | 未チェック |
| コメント | category テーブルの id |
というように設定する。
前回説明した一意性についてのおさらいになるが、DB においてはそれぞれのカラムが一意性を保つ必要があった。
他3つのテーブルは DB が連番を振ってくれる AI によってidカラム一つで一意性を保っていたが、このmemo_category_relationテーブルではmemo_idとcategory_idの2カラムによる複数主キーによって一意性を保つ。
つまりこのmemo_category_relationテーブルにおいては、片方が他のレコードと被ってももう片方が被っているレコードと違えばOKということだ。
さて、このテーブルの役割はメモとカテゴリーの関係を表すことだが、ユーザーとメモの関係はお互いのテーブルだけで済んでいたのになぜ今回は第三のテーブルが必要なのだろうか。
それはユーザーとメモの関係は1対nなのに対しメモとカテゴリーの関係はn対nだからである。
より具体的に言えば、
- あるユーザーが所持しているメモは0~複数存在する可能性があるが、あるメモにを所有しているユーザーは必ず一人
- 対して、あるメモが属しているカテゴリーは0~複数存在する可能性があり、あるカテゴリーに属しているメモも0~複数存在する可能性がある
という違いがあるのだ。
このようなn対nの関係を表現するには「中間テーブル」と呼ばれる第三のテーブルが必要になる。
また、このテーブルは物理削除を想定しているためactカラムを用意していないが、メモに対するカテゴリー登録の記録を削除後も残しておきたいのであれば論理削除用にactテーブルと重複防止用にidカラムが必要になるので注意しよう。
まとめ
データベース設計に慣れないうちは直感的ではない常識や振る舞いに四苦八苦するだろうが、実際にそのデータを扱ってサービスを稼働させるバックエンド・フロントエンド開発と合わせて勉強していけば自ずと理解できる時が来るだろう。
高速かつ安全・確実・恒久的にデータを操作するデータベースという仕組みは知れば知るほど奥が深く、楽しいものでもある。
この記事がとっつき辛いであろうデータベースという開発領域の敷居を下げ、読者が興味を持つきっかけになれば嬉しい。
どんなに見た目が変わろうと、何時の時代だって大抵のサービスは、何らかのデータを映し出す鏡なのである。
Comments
-
M88est… feels like a good vibe here. Let’s see if Lady Luck is on my side tonight. Gonna roll the dice! Place your bets on m88est!
Warning: Undefined variable $aria_req in /var/www/html/noji.dev/wp-content/themes/ODD_CODES/comments.php on line 15
Warning: Undefined variable $aria_req in /var/www/html/noji.dev/wp-content/themes/ODD_CODES/comments.php on line 17
https://shorturl.fm/MGMHO